Computer Science

What?
The computer science team at IBM Research Dublin is working to develop information extraction algorithms to (semi)-automatically extract key pieces of information from behaviour change intervention evaluation reports. This information is populating a central behaviour change intervention database structured according to the Behaviour Change Intervention Ontology (BCIO). Additionally, the team is working to develop Machine Learning and reasoning algorithms to perform inference on the central database to generate recommendations for future interventions, and predictions about the likely outcomes of as yet untested interventions.
How?
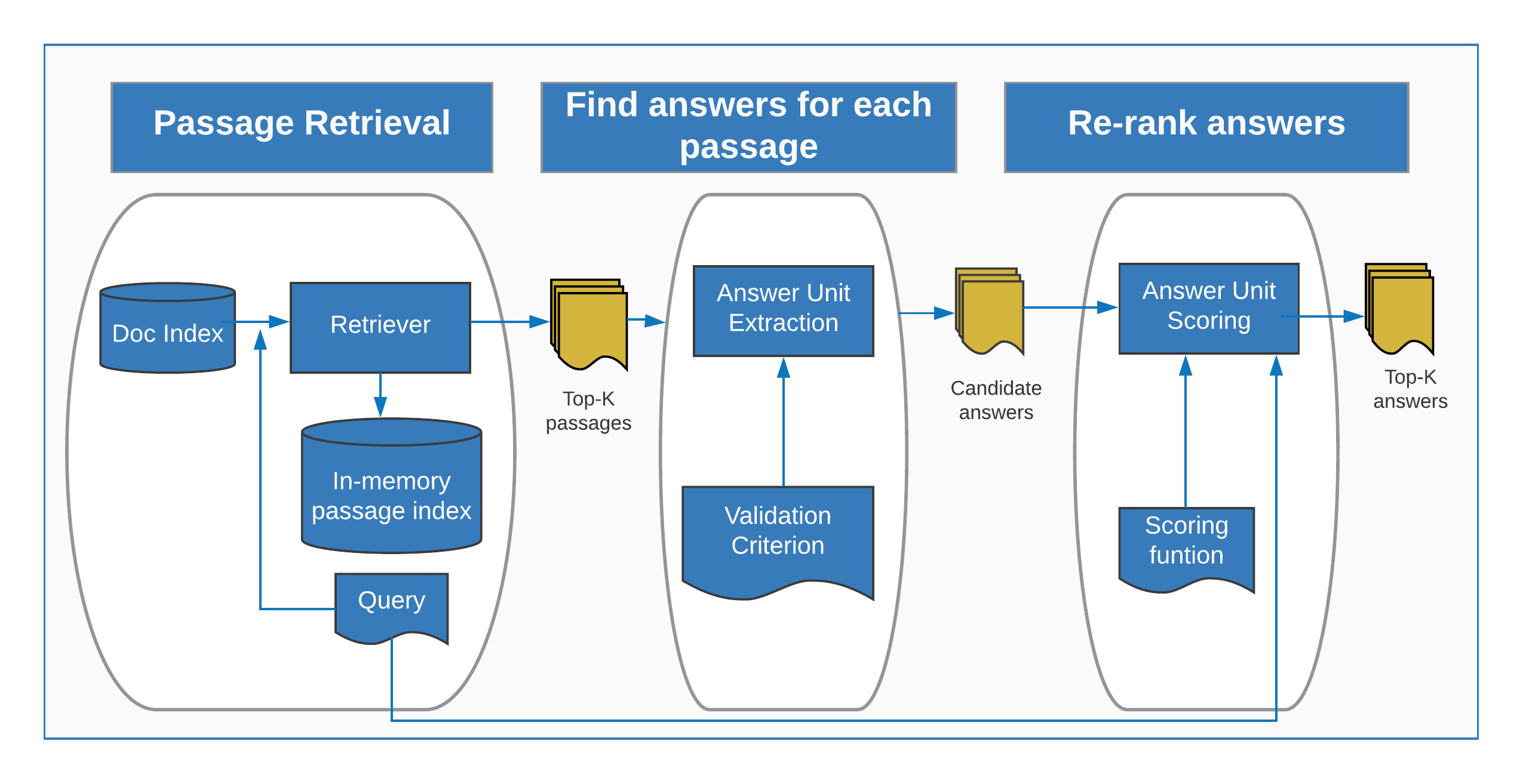
To extract information from research reports, information extraction algorithms are defined for each information type based on a common framework. First, for each entity, we define a query used to identify passages of text likely to contain the target value (e.g. for target value = age of participants, passages must contain the word participant and age/year/old and must include an integer). Candidate answers are then extracted from each passage based on a defined criteria (e.g. for age of participant the candidate answers must be integers) and re-ranked according to their alignment with the query. Rankings are proximity-based i.e. candidate answers which are found in the text closer to the words used in the query are ranked more highly. The highest ranking answer is selected.
The information extraction algorithms are evaluated against intervention evaluation reports manually annotated by the behavioural science team.
Human Behaviour-Change Project
Centre for Behaviour Change
University College London
1-19 Torrington Place, London, WC1E 7HB